Evaluation of models trained on NW¶
Evaluation of models trained on NW sample of chips
import json
import glob
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import urbangrammar_graphics as ugg
path = "../../urbangrammar_samba/spatial_signatures/ai/nw_*/json/"
results = glob.glob(path + "*")
with open(results[0], "r") as f:
result = json.load(f)
[i for i in result if "meta" in i]
['meta_n_class', 'meta_class_map', 'meta_class_names', 'meta_chip_size']
names = [i[58:-5] + "_" + i[50:52] for i in results]
names
['efficientnet_pooling_256_3_16',
'vgg19_pooling_256_3_16',
'efficientnet_flatten_128_3_32',
'efficientnet_flatten_256_3_32',
'efficientnet_flatten_512_3_32',
'efficientnet_pooling_128_3_32',
'efficientnet_pooling_256_3_32',
'efficientnet_pooling_512_3_32',
'resnet50_flatten_128_3_32',
'resnet50_flatten_256_3_32',
'resnet50_flatten_512_3_32',
'resnet50_pooling_128_3_32',
'resnet50_pooling_256_3_32',
'resnet50_pooling_512_3_32',
'vgg19_flatten_128_3_32',
'vgg19_flatten_256_3_32',
'vgg19_flatten_512_3_32',
'vgg19_pooling_128_3_32',
'vgg19_pooling_256_3_32',
'vgg19_pooling_512_3_32',
'efficientnet_pooling_256_3_64',
'vgg19_pooling_256_3_64',
'efficientnet_pooling_256_3_08',
'vgg19_pooling_256_3_08']
accuracy = pd.DataFrame(columns=["global"] + result["meta_class_names"], index=pd.MultiIndex.from_product([names, ["train", "val", "secret"]]))
for r in results:
with open(r, "r") as f:
result = json.load(f)
accuracy.loc[(result["model_name"]+ "_" + r[50:52], "train")] = [result["perf_model_accuracy_train"]] + result["perf_within_class_accuracy_train"]
accuracy.loc[(result["model_name"]+ "_" + r[50:52], "val")] = [result["perf_model_accuracy_val"]] + result["perf_within_class_accuracy_val"]
accuracy.loc[(result["model_name"]+ "_" + r[50:52], "secret")] = [result["perf_model_accuracy_secret"]] + result["perf_within_class_accuracy_secret"]
sns.set_theme(style="white")
accuracy
| global | centres | periphery | countryside | ||
|---|---|---|---|---|---|
| efficientnet_pooling_256_3_16 | train | 0.690413 | 0.667913 | 0.696415 | 0.687406 |
| val | 0.681598 | 0.462719 | 0.688869 | 0.68674 | |
| secret | 0.679615 | 0.502315 | 0.685129 | 0.683583 | |
| vgg19_pooling_256_3_16 | train | 0.71285 | 0.683562 | 0.715533 | 0.713139 |
| val | 0.687897 | 0.400832 | 0.688503 | 0.709091 | |
| ... | ... | ... | ... | ... | ... |
| efficientnet_pooling_256_3_08 | val | 0.57277 | 0.608934 | 0.388869 | 0.630643 |
| secret | 0.574561 | 0.602028 | 0.408942 | 0.63112 | |
| vgg19_pooling_256_3_08 | train | 0.594761 | 0.616865 | 0.43194 | 0.642681 |
| val | 0.58644 | 0.606706 | 0.405567 | 0.644179 | |
| secret | 0.584357 | 0.602026 | 0.418351 | 0.638548 |
72 rows × 4 columns
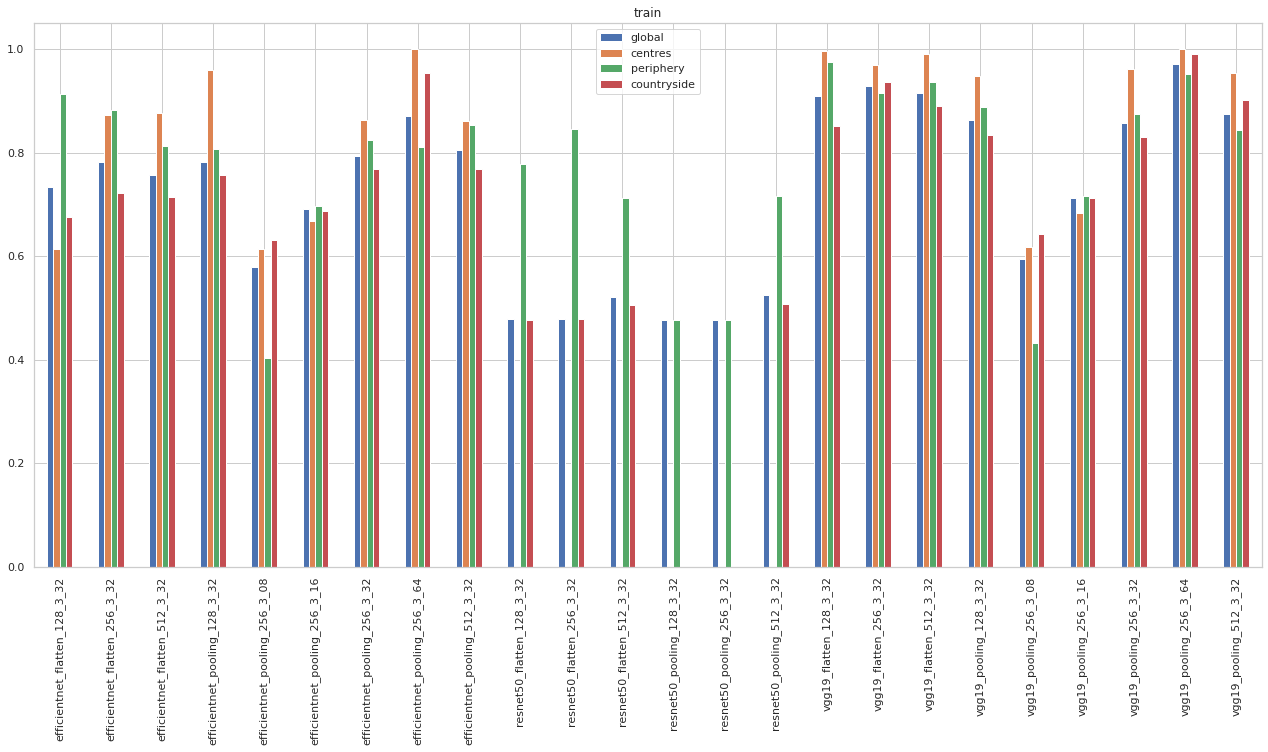
accuracy.xs('train', level=1).sort_index().plot.bar(figsize=(22, 10), title="train")
<AxesSubplot:title={'center':'train'}>
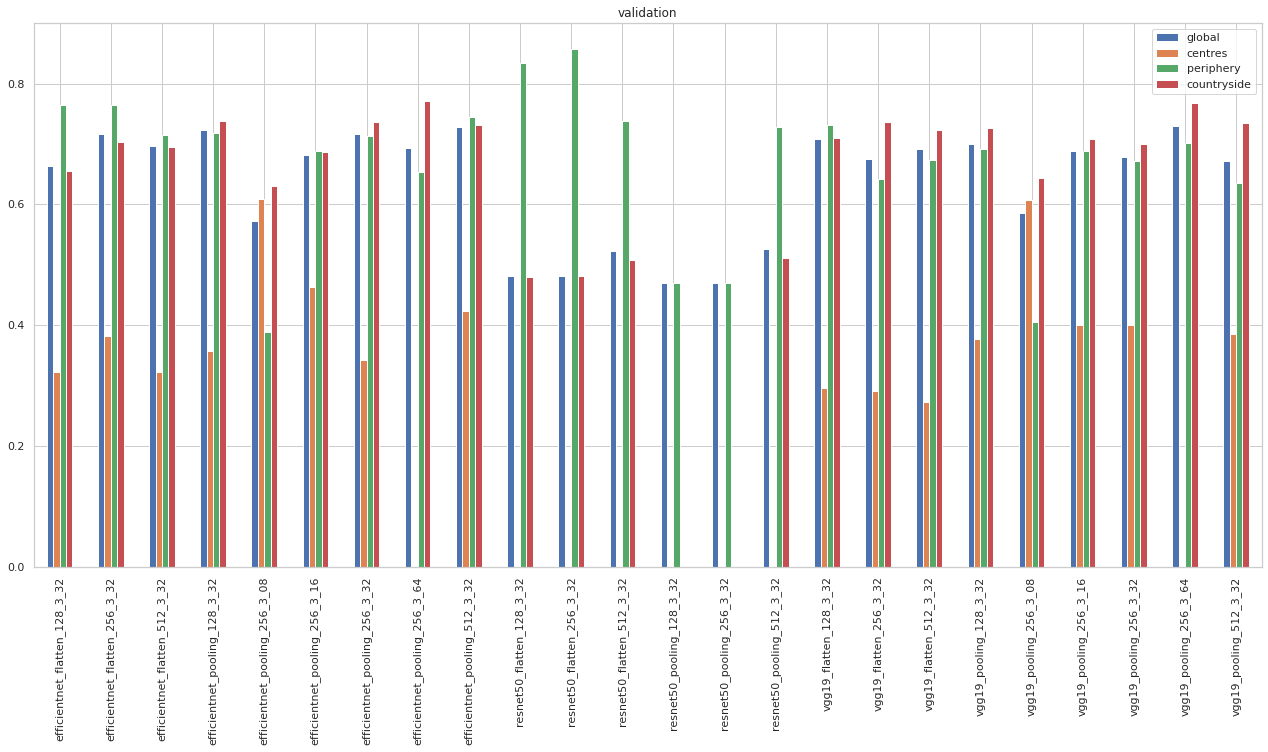
accuracy.xs('val', level=1).sort_index().plot.bar(figsize=(22, 10), title="validation")
<AxesSubplot:title={'center':'validation'}>
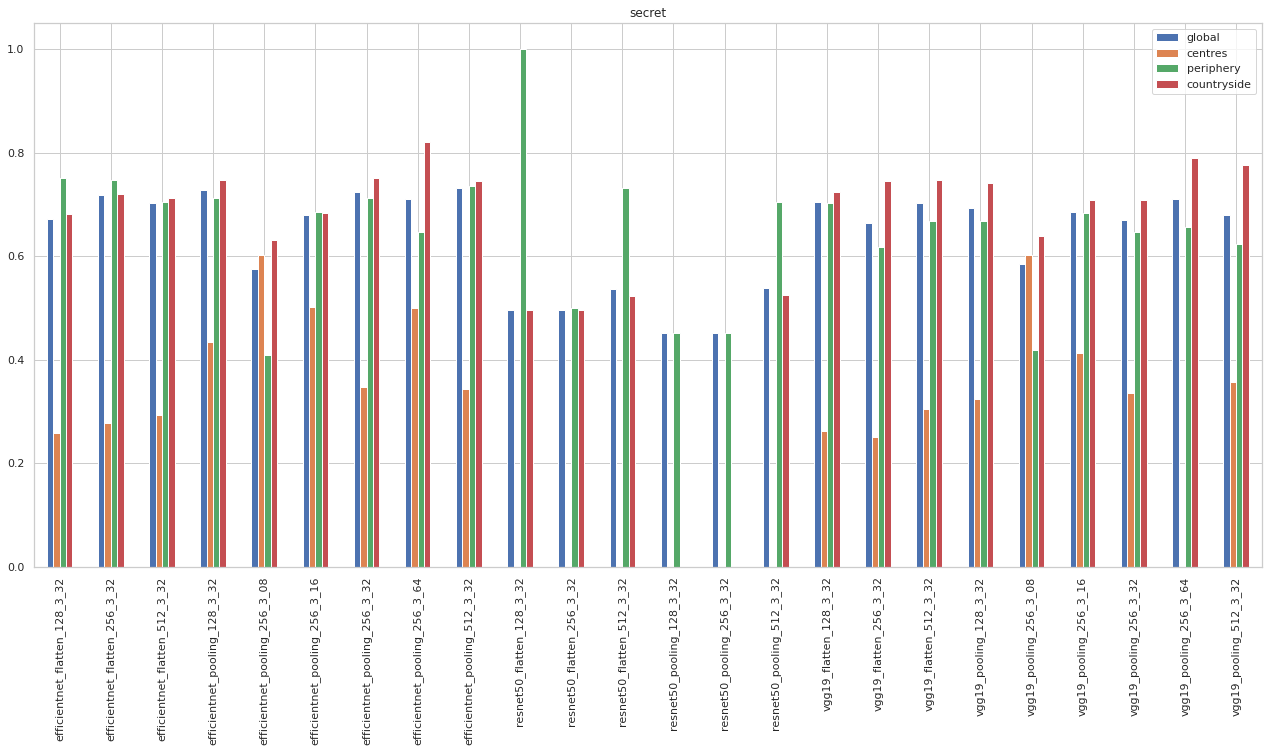
accuracy.xs('secret', level=1).sort_index().plot.bar(figsize=(22, 10), title="secret")
<AxesSubplot:title={'center':'secret'}>
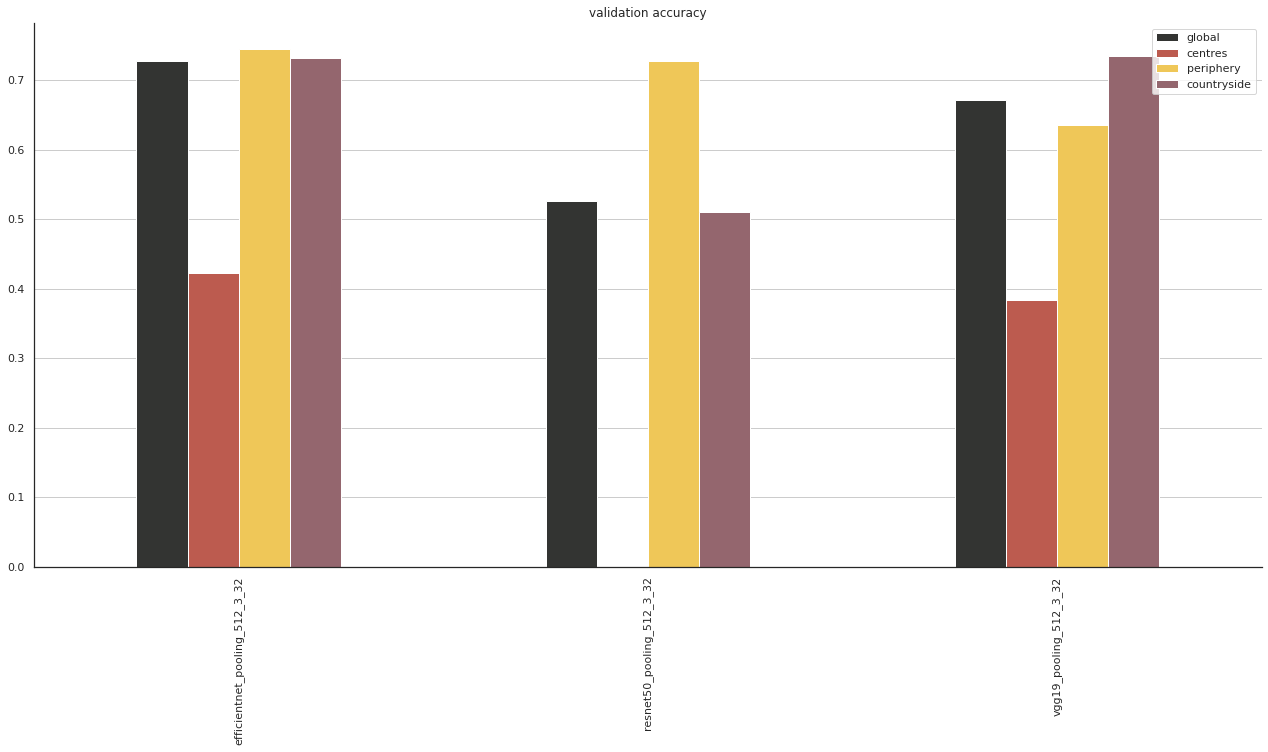
ax = accuracy.xs('val', level=1)[accuracy.xs('val', level=1).index.str.contains("pooling_512_3_32")].sort_index().plot.bar(figsize=(22, 10), title="validation accuracy", cmap=ugg.CMAP)
sns.despine()
ax.grid(axis='y')
plt.savefig("figs/comp1.pdf")
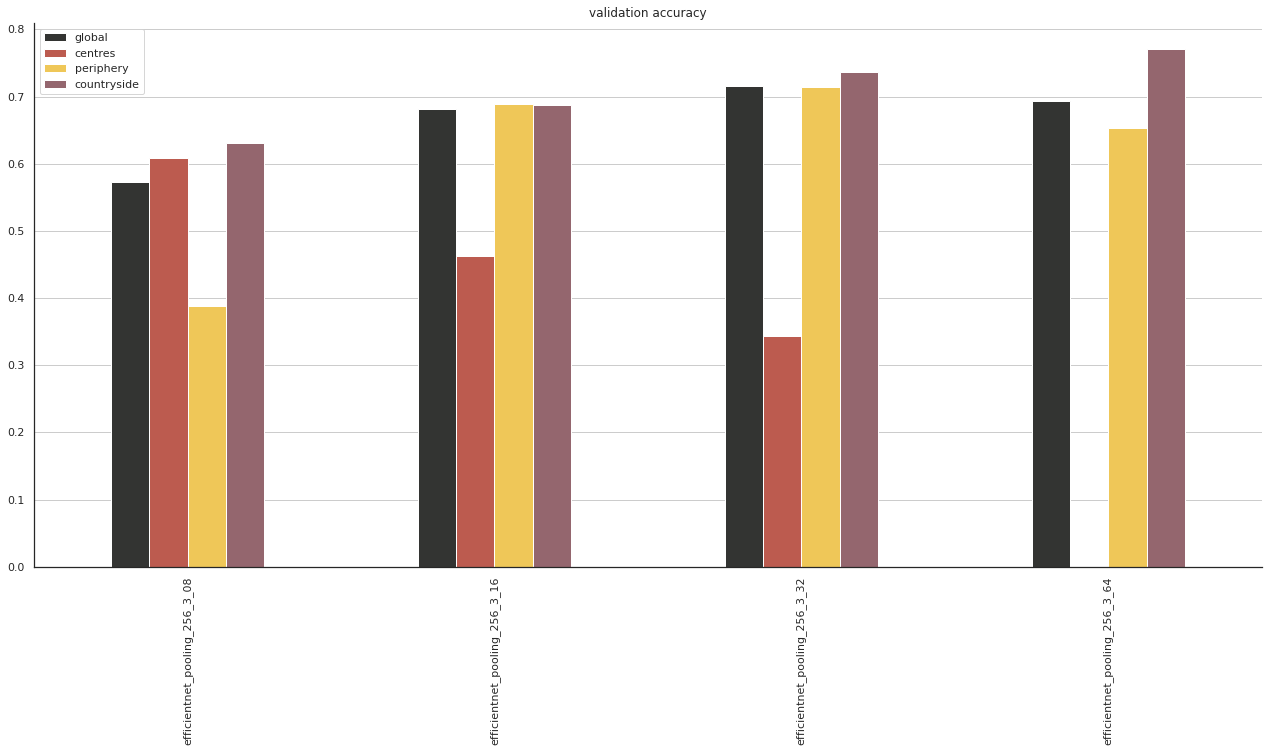
ax = accuracy.xs('val', level=1)[accuracy.xs('val', level=1).index.str.contains("efficientnet_pooling_256_3")].sort_index().plot.bar(figsize=(22, 10), title="validation accuracy", cmap=ugg.CMAP)
sns.despine()
ax.grid(axis='y')
plt.savefig("figs/comp2.pdf")
regression¶
regr_input = pd.DataFrame(columns=["global_validation_acc", "global_secret_acc", "architecture", "top_layer", "neurons", "chip_size"], index=names)
for r in results:
with open(r, "r") as f:
result = json.load(f)
regr_input.loc[result["model_name"]+ "_" + r[47:49]] = [result["perf_model_accuracy_val"], result["perf_model_accuracy_secret"], result["model_name"][:-14], result["model_bridge"], result["model_toplayer"], result['meta_chip_size']]
regr_input
| global_validation_acc | global_secret_acc | architecture | top_layer | neurons | chip_size | |
|---|---|---|---|---|---|---|
| efficientnet_pooling_256_3_08 | 0.57277 | 0.574561 | efficientnet | pooling | 256 | 8 |
| vgg19_pooling_256_3_08 | 0.58644 | 0.584357 | vgg19 | pooling | 256 | 8 |
| efficientnet_pooling_256_3_64 | 0.693069 | 0.710526 | efficientnet | pooling | 256 | 64 |
| vgg19_pooling_256_3_64 | 0.729373 | 0.710526 | vgg19 | pooling | 256 | 64 |
| efficientnet_pooling_256_3_16 | 0.681598 | 0.679615 | efficientnet | pooling | 256 | 16 |
| vgg19_pooling_256_3_16 | 0.687897 | 0.685506 | vgg19 | pooling | 256 | 16 |
| efficientnet_pooling_256_3_32 | 0.715764 | 0.723534 | efficientnet | pooling | 256 | 32 |
| resnet50_pooling_512_3_32 | 0.526274 | 0.538339 | resnet50 | pooling | 512 | 32 |
| resnet50_flatten_128_3_32 | 0.481157 | 0.495888 | resnet50 | flatten | 128 | 32 |
| resnet50_pooling_128_3_32 | 0.469745 | 0.451844 | resnet50 | pooling | 128 | 32 |
| vgg19_pooling_256_3_32 | 0.678609 | 0.669408 | vgg19 | pooling | 256 | 32 |
| resnet50_flatten_256_3_32 | 0.481423 | 0.495622 | resnet50 | flatten | 256 | 32 |
| vgg19_pooling_128_3_32 | 0.69931 | 0.692226 | vgg19 | pooling | 128 | 32 |
| efficientnet_flatten_256_3_32 | 0.715764 | 0.717697 | efficientnet | flatten | 256 | 32 |
| vgg19_flatten_128_3_32 | 0.708333 | 0.705492 | vgg19 | flatten | 128 | 32 |
| efficientnet_flatten_128_3_32 | 0.663482 | 0.671266 | efficientnet | flatten | 128 | 32 |
| efficientnet_pooling_128_3_32 | 0.723726 | 0.728575 | efficientnet | pooling | 128 | 32 |
| vgg19_flatten_512_3_32 | 0.692144 | 0.702839 | vgg19 | flatten | 512 | 32 |
| vgg19_flatten_256_3_32 | 0.675425 | 0.664632 | vgg19 | flatten | 256 | 32 |
| efficientnet_pooling_512_3_32 | 0.727972 | 0.731228 | efficientnet | pooling | 512 | 32 |
| vgg19_pooling_512_3_32 | 0.67224 | 0.679491 | vgg19 | pooling | 512 | 32 |
| resnet50_flatten_512_3_32 | 0.522824 | 0.537278 | resnet50 | flatten | 512 | 32 |
| efficientnet_flatten_512_3_32 | 0.697187 | 0.702839 | efficientnet | flatten | 512 | 32 |
| resnet50_pooling_256_3_32 | 0.469745 | 0.451844 | resnet50 | pooling | 256 | 32 |
import statsmodels.api as sm
model = sm.OLS(regr_input.global_validation_acc.values.astype(float), sm.add_constant(pd.get_dummies(regr_input[["architecture", "top_layer", "neurons", "chip_size"]], drop_first=True)))
results = model.fit()
results.summary()
| Dep. Variable: | y | R-squared: | 0.961 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.941 |
| Method: | Least Squares | F-statistic: | 46.59 |
| Date: | Fri, 14 Jan 2022 | Prob (F-statistic): | 3.25e-09 |
| Time: | 16:30:06 | Log-Likelihood: | 62.322 |
| No. Observations: | 24 | AIC: | -106.6 |
| Df Residuals: | 15 | BIC: | -96.04 |
| Df Model: | 8 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 0.5795 | 0.024 | 24.103 | 0.000 | 0.528 | 0.631 |
| architecture_resnet50 | -0.2091 | 0.013 | -16.583 | 0.000 | -0.236 | -0.182 |
| architecture_vgg19 | -0.0068 | 0.011 | -0.636 | 0.534 | -0.030 | 0.016 |
| top_layer_pooling | 0.0051 | 0.011 | 0.472 | 0.644 | -0.018 | 0.028 |
| neurons_256 | -0.0015 | 0.013 | -0.114 | 0.911 | -0.030 | 0.027 |
| neurons_512 | 0.0155 | 0.013 | 1.176 | 0.258 | -0.013 | 0.044 |
| chip_size_16 | 0.1051 | 0.023 | 4.610 | 0.000 | 0.057 | 0.154 |
| chip_size_32 | 0.1143 | 0.020 | 5.785 | 0.000 | 0.072 | 0.156 |
| chip_size_64 | 0.1316 | 0.023 | 5.771 | 0.000 | 0.083 | 0.180 |
| Omnibus: | 3.305 | Durbin-Watson: | 2.601 |
|---|---|---|---|
| Prob(Omnibus): | 0.192 | Jarque-Bera (JB): | 1.427 |
| Skew: | -0.159 | Prob(JB): | 0.490 |
| Kurtosis: | 1.848 | Cond. No. | 12.8 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.